Introduction #
Database: An organised collection of data that can be easily accessed either as relational databases or flat files.
Relational Database:
In a relational database, data is stored in tables. Each entity is something important that you want to store information about, like a person, product, or order.
To keep things organised, a relational database creates separate tables for each different type of entity. For example, you might have one table for customers, another for orders, and another for products. Each table holds information related to that specific entity, like a customer’s name, an order’s date, or a product’s price.
So, a relational database helps organise information by treating each type of entity separately in different tables, making it easier to manage and understand the data.
Flat File:
A flat file is a type of database that stores all its data in just one file. This file usually contains information about one type of entity, like a list of customers or products. Each piece of information is stored in rows, and each row has different attributes (like name, age, or price) for that entity.
For example, a flat file might just have a list of customers and their contact details, all in one file. It’s simpler than a relational database, but it’s not as organised or flexible.
To manage these databases, DBMS (database management systems) are used, such as the software MySQL, PostgreSQL, MongoDB
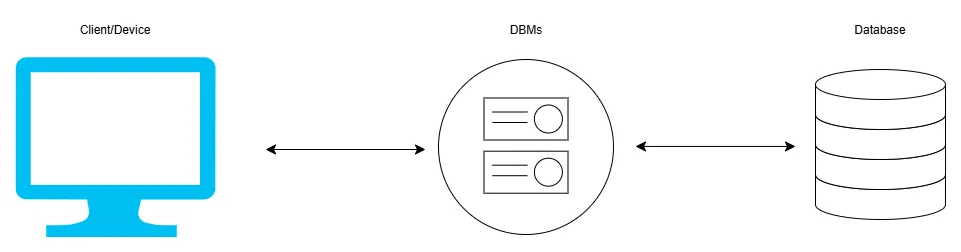
A DBMS is a software system designed to manage databases, providing tools for creating, protecting, reading, updating, and deleting data. It acts as an interface between users or applications and the database, allowing them to interact with the data in a structured and organised manner.
Types of DBMS #
- Relational DBMS
- Non-Relational DBMS
Relational DBMS: In this DBMS, data is stored in a table format with rows and columns; SQL is the standard language for querying and managing data in an RDBMS. (An example of a relational DBMS is the software MySQL or MariaDB)
| Roll No | Name | Class |
| 1 | Bob | 6th |
| 2 | Charlie | 5th |
| 3 | Alice | 5th |
| 4 | Amar | 10th |
Non-Relational DBMS: In this DBMS, data is stored in key-value pairs. Instead of structured tables, data is stored in formats like JSON or BSON, where each document is self-contained and can have different fields. This model is ideal for unstructured or semi-structured data, providing scalability and flexibility, especially for dynamic or complex datasets (An example of a non-relational DBMS is the software MongoDB)
{
"Roll No": "1",
"Class": "6th",
"Name": "Bob"
}SOL: It stands for Structured Query Language. SQL is used for updating, deleting, and inserting data in tables or Relational databases. It is a standard language used to manage and manipulate databases and allows users to create, modify, and query databases efficiently.
SQL Keywords are case-insensitive. In MySQL, case-insensitive is an option that can be turned on and off.
SQL Create Command:
Used for creating tables and has the following syntax:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
);Example:
Creating a new “Movies” table:
CREATE TABLE Movies (
MovieID INT PRIMARY KEY,
MovieTitle VARCHAR(255) NOT NULL,
MovieCompany VARCHAR(255),
DatePublished DATE,
DirectorName VARCHAR(255)
);
This command creates a “Movies” table with columns for movie ID, title, production company, publication date, and director’s name. The “MovieID” is set as the primary key, ensuring each record is unique. The “MovieTitle” cannot be left empty due to the “NOT NULL” constraint.
ORDER Command: Sorts the result set by one or more columns.
- Example: To sort movies by their release date in descending order (newest first):
SELECT MovieTitle, DatePublishedFROM MovieORDER BY DatePublished DESC;
SQL Join Command: Combines rows from two or more tables based on a related column
Example: To list movie titles along with their directors’ names:
SELECT Movie.MovieTitle, Director.DirectorName
FROM Movie
JOIN Director
ON Movie.DirectorName = Director.DirectorName;
This query retrieves movie titles and their corresponding directors by matching the “DirectorName” field in both the “Movie” and “Director” tables
SQL Insert into Command:
Used for inserting data into tables with the following syntax:
INSERT INTO table_name (column1, column2 )
VALUES (value1, value2 );- A row of a database table known as a record or type.
- A column of a database table is known as an attribute.
SQL Select Command:
Used for retrieving data from the table.
Syntax:
SELECT column1, column2
FROM table_nameExample:
To get the titles and release dates of movies published between 2020 and 2024:
SELECT MovieTitle, DatePublished
FROM Movie
WHERE DatePublished BETWEEN '2020-01-01' AND '2024-12-31'
ORDER BY DatePublished;
This query selects the movie titles and their publication dates from the “Movie” table, filters the results to include only those released between 1st January 2020 and 31st December 2024, and orders them by publication date.
How Does SQL Work? #
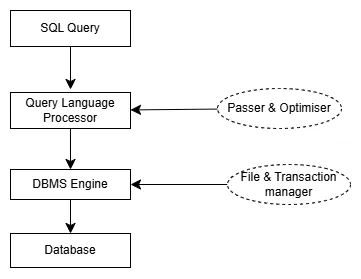
Structured Query Language (SQL) is a standardized language designed for managing and manipulating relational databases. It enables users to define, retrieve, and manipulate data efficiently. When an SQL query is executed, the database management system (DBMS) follows a series of steps to process and return the desired results.
The initial step in processing an SQL query is parsing, where the query statement is tokenized. During this phase, the DBMS checks the query for correct syntax and validates the semantics to ensure that the referenced tables and columns exist and are accessible. This ensures that the query is both well-formed and meaningful within the context of the database schema.
Following parsing, the DBMS undertakes optimisation to ensure that queries run efficiently. The optimiser evaluates various execution plans and selects the most efficient one based on factors such as available indexes, data distribution, and join methods. This process is crucial for enhancing performance, especially when dealing with large datasets.
Once optimised, the query execution involves several key SQL clauses:
Optimising: The process of ensuring your queries are running efficiently
From: It is used to specify the tables from which data is fetched
Where: It is used to filter records based on given conditions
Join: Used to combine data from tables based on common fields
Group By: It is used to group records based on a specific requirement
Having: Used to filter groups
Select: Used to retrieve data from the table
Limit: Used to specify how many rows are returned
SQL Constraints #
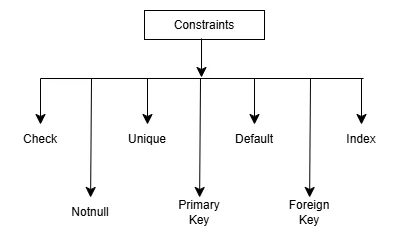
These constraints are also known as Integrity constraints.
SQL Constraints: are the rules and restrictions applied on the data in a table
Primary Key:
A Primary Key is a unique identifier for each record in the table. It ensures that no two rows have the same value for this column. A table can only have one primary key, but that key can consist of multiple columns (composite primary key).
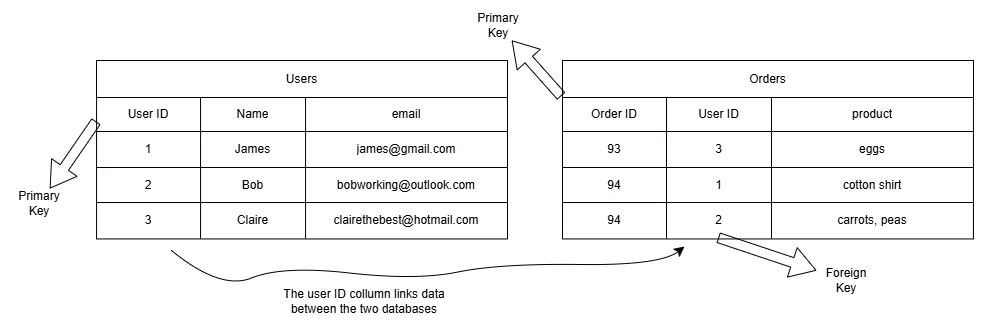
Foreign Key:
A Foreign Key is an attribute in one table that links to the primary key of another table. It is used to maintain referential integrity between the two tables. The foreign key value in the child table must match a value in the primary key column of the parent table.
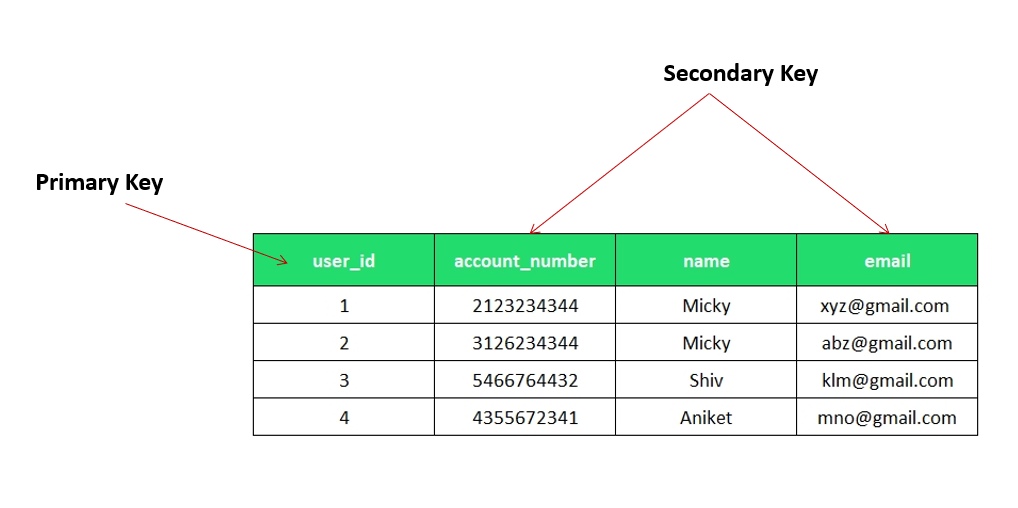
Secondary Key:
A Secondary Key allows a database to be searched quickly for non-unique data. It is not necessarily used for enforcing uniqueness but helps in faster lookups. An example of this could be:
At a school, each student has a unique Student ID as their primary key. However, when teachers need to quickly look up student records, they often search by email address or phone number, as students may not remember their Student ID.
To optimize these searches, the schools database can establish a secondary key on the email address or phone number attributes. This allows for faster lookups without affecting the uniqueness of the primary key
Check:
The Check constraint ensures that all values in a column meet a specific condition or criteria. For example, you can ensure that an employee’s salary is greater than a certain amount, or that a person’s age is greater than 18. If the condition is violated, the database will reject the insertion or update.
Example:
CREATE TABLE Employees (
EmployeeID INT,
Name VARCHAR(100),
Age INT,
CHECK (Age >= 18)
);
Unique:
The Unique constraint ensures that all values in a column or a combination of columns are unique. No two rows in the table can have the same value for the specified column(s). This is similar to a Primary Key, but it allows for the existence of NULL values (which a primary key does not).
Example:
CREATE TABLE Users (
UserID INT PRIMARY KEY,
Email VARCHAR(100) UNIQUE
);
Not Null:
The Not Null constraint ensures that a column cannot have a NULL value. It is useful when you want to make sure that a column always has data and no empty or missing values are allowed.
Example:
CREATE TABLE Students (
StudentID INT,
Name VARCHAR(100) NOT NULL
);
Default:
The Default constraint provides a default value for a column when no value is specified during an insert operation. This ensures that if no data is provided for a column, a predefined value will be used instead.
Example:
CREATE TABLE Products (
ProductID INT,
ProductName VARCHAR(100),
Price DECIMAL(10, 2) DEFAULT 0.0
);
Index:
An Index is used to improve the speed of data retrieval operations on a table. Indexes are created on columns that are frequently used in search conditions (e.g., WHERE clauses). Indexes can speed up the search process, but they can also slow down insert and update operations because the index needs to be updated whenever the table data changes.
Example:
CREATE INDEX idx_name ON Students (Name);SQL Joins #
SQL joins are used to combine rows from two or more tables based on a common attribute. They allow for meaningful data retrieval by linking related tables.
Inner Join #
The INNER JOIN returns only the rows that have matching values in both tables. If no match is found, the row is excluded from the result.
For example, joining an employees table with a departments table on department_id will return only employees who are assigned to a valid department:
SELECT employees.name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id;
Left Join (Left Outer Join) #
A LEFT JOIN returns all rows from the left table and only the matching rows from the right table. If no match is found, NULL values are returned for the right table’s columns.
This is useful when you need a complete list of records from one table while still including any related data from another table:
SELECT employees.name, departments.department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.department_id;
Right Join (Right Outer Join) #
A RIGHT JOIN is similar to a left join but returns all rows from the right table and only matching rows from the left table. If no match is found, NULL values appear in the left table’s columns.
Full Join (Full Outer Join) #
A FULL JOIN combines the results of both left and right joins. It returns all records when there is a match in either table and fills in NULL values where data is missing.
Handling Data #
Capturing Data
Capturing data means collecting information and entering it into a database. The method used depends on the situation:
For example, if people are participating in a survey, their responses will need to be manually entered into the database. Data is also captured when people pay cheques. Banks scan cheques using Magnetic Ink Character Recognition (MICR). All of the details excluding the amount are printed in a special magnetic ink which can be recognised by a computer but the amount must be entered manually. Optical Mark Recognition (OMR) is used for multiple choice questions on a test. Other forms use Optical Character Recognition (OCR).
Selecting and Managing Data
Selecting the right data is essential for effective data analysis. This involves choosing data that meets specific criteria to make processing more efficient:
- Filtering Data: Selecting data that fits certain conditions to reduce the amount processed. For example, a speed camera system captures images of cars exceeding a set speed limit. It then stores only the number plates, omitting other details.
- Using SQL for Data Management: Structured Query Language (SQL) helps in sorting, restructuring, and selecting specific data subsets. For instance, you can use SQL to retrieve movies released between 2020 and 2024, ordered by their release date as shown in the SQL select command example before
Exchanging Data
Exchanging data refers to transferring collected information between systems without manual intervention. A common method is:
- Electronic Data Interchange (EDI): EDI allows computers to exchange data directly, streamlining processes like order placements and inventory management.
SQL Errors #
Syntax Errors #
A syntax error occurs when an SQL query does not follow the correct SQL grammar, such as misspelled keywords, incorrect punctuation, or missing clauses.
Example:
SELECT * FRM employees;// Incorrect keyword ("FRM" should be "FROM")
Transaction Errors #
Transactions are used to ensure that a group of SQL operations is executed completely or not at all. A transaction error occurs when one or more statements in a transaction fail, causing an inconsistent database state.
Example:
BEGIN TRANSACTION;
DELETE FROM accounts WHERE account_id = 10;
UPDATE accounts SET balance = balance - 100 WHERE account_id = 20;
COMMIT;
// If the second statement fails, the delete operation may still be executed, leading to inconsistencies.
Semantic Errors #
A semantic error happens when an SQL statement is technically correct in syntax but logically incorrect due to incorrect use of database objects or operations.
Example:
SELECT department_name FROM employees;
//"department_name" may not exist in the "employees" table
Data Type Errors #
Data type errors occur when the value assigned to a column does not match its expected data type.
Example:
INSERT INTO users (user_id, name, age) VALUES (101, 'Alice', 'twenty-five');
// Error: "age" column expects an integer, but a string is provided.
Constraint Errors #
Constraint errors occur when a query violates database constraints such as PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL, or CHECK constraints.
Example:
INSERT INTO students (student_id, name) VALUES (1, 'John');
INSERT INTO students (student_id, name) VALUES (1, 'Sarah');
// Error: Duplicate primary key value (student_id = 1)Vulnerabilities #
SQL Injection is a type of security vulnerability that allows attackers to interfere with the queries an application makes to its database. By inserting or “injecting” malicious SQL code into input fields, attackers can manipulate the database in unintended ways. This can lead to unauthorized access, data loss, or even complete system compromise
How SQL Injection Works
SQL Injection typically occurs when an application includes untrusted data in a SQL query without proper validation or escaping. For example, consider a login form that asks for a username and password. If the application constructs a SQL query by directly inserting user-provided values without sanitization, an attacker could input the following:
- Username:
' OR '1'='1 - Password:
' OR '1'='1
This could transform the intended query into:
SELECT * FROM Users WHERE Username = '' OR '1'='1' AND Password = '' OR '1'='1';
Since '1'='1' is always true, this query would return all records from the Users table, potentially granting unauthorized access.
Types of SQL Injection #
In-band SQL Injection: The attacker uses the same communication channel to both launch the attack and gather results.
Error-based SQL Injection: The attacker relies on error messages thrown by the database server to gather information about the structure of the database.
Blind SQL Injection: The attacker asks the database a true or false question and determines the answer based on the application’s response.
Out-of-band SQL Injection: The attacker uses different channels to exfiltrate data, often relying on features like sending DNS or HTTP requests
A more detailed info about sql injection can be found in the next knowledge base



