In today’s digital world, cybersecurity firms hold immense responsibility. Their clients rely on them to protect sensitive data, prevent cyber threats, and ensure business continuity. But what happens when the very company entrusted with security becomes the cause of a widespread outage?
This is exactly what happened in July 2024, when CrowdStrike (a major cybersecurity provider) released an update that inadvertently triggered one of the largest IT outages in history. Millions of computers worldwide crashed, disrupting industries ranging from airlines to emergency services. The fallout was immense—reputational damage, financial loss, and a wave of scepticism from stakeholders.
This article breaks down the event as it happened, the lessons learned, and why communication plays a crucial role in damage control during such crises.
July 19, 2024: The Faulty Update That Crashed the World
It started as a routine update — a new patch to enhance CrowdStrike’s Falcon security platform. But within hours of its deployment, chaos erupted. The update contained a critical flaw that caused Windows computers to crash, sending businesses into disarray. More than 8.5 million devices were affected, with companies and public services scrambling to get their systems back online. Microsoft’s Windows operating system, which powers everything from airport check-in kiosks to hospital networks, was particularly impacted.
The disruption was immediate and far-reaching. Airlines had to ground flights as their scheduling and reservation systems failed. Hospitals faced delays in accessing critical patient data, and emergency services in some areas struggled with system failures. Even retail businesses experienced transaction failures, leading to financial losses.
For those interested, the culprit of the bug was a flaw in the softwares Content Interpreter Module, which caused out-of-bounds memory reads which would usually only cause the program to crash. However, in these circumstances, CrowdStrike falcon was running as a device driver in the Windows kernel. This meant that when the application crashed from an out-of-bounds memory read, it placed the device into kernel panic. The full technical incident report from CrowdStrike can be found here.
July 20-29, 2024: The Response and Recovery Efforts
As the crisis unfolded, all eyes turned to CrowdStrike. The company initially struggled to diagnose the issue and provide a clear resolution. However, within 48 hours, they identified the root cause: a bug within their Falcon update that led to system crashes on Windows devices. CrowdStrike quickly collaborated with Microsoft and IT teams worldwide to develop a fix. The company issued manual remediation steps, but due to the sheer scale of the incident, recovery took time. By July 29, CrowdStrike reported that 99% of affected Windows sensors were back online. While the crisis was technically resolved, the reputational damage had already been done.
The Aftermath: Reputational and Financial Impact
The CrowdStrike outage had significant repercussions, particularly on its standing within the cybersecurity industry. Clients and analysts alike questioned how a company specializing in security could have released such a flawed update.
One of the biggest concerns was trust. CrowdStrike’s customers—some of the world’s largest enterprises—rely on the company to prevent downtime, not cause it. The outage raised doubts about their internal testing and quality assurance processes. Would customers still feel confident relying on a company that had inadvertently triggered one of the worst IT outages in recent history?
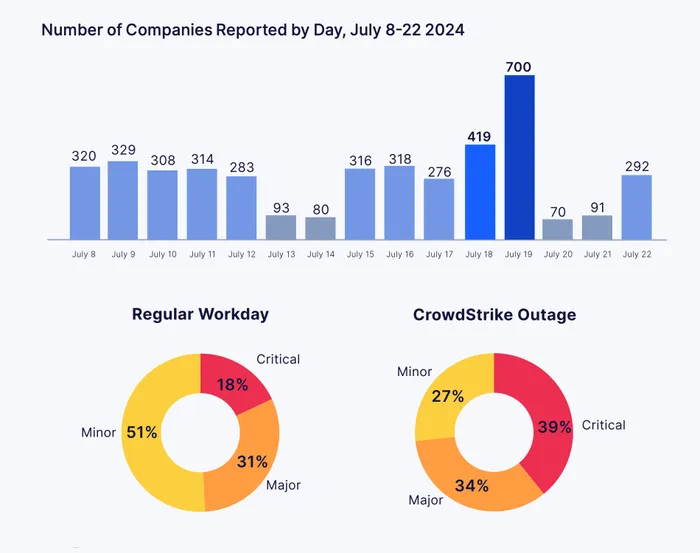
Financially, the damage was also severe. CrowdStrike’s stock price plummeted by nearly 25%, wiping out over $20 billion in market value in a matter of days. Investors worried about long-term financial consequences, especially as the company had to offer discounts to affected clients to maintain customer retention. CNN estimated that there was a $1.94 billion impact on the healthcare sector and the company also projected a $30 million hit to its subscription revenue in the following quarter.
Despite this, CrowdStrike demonstrated resilience. By the end of the fiscal quarter, they reported a 29% increase in revenue, showcasing that while the short-term impact was painful, strong customer loyalty and proactive measures helped them regain some ground.
Could This Happen to Other Companies?
Absolutely. CrowdStrike’s incident is a textbook example of how even the most trusted cybersecurity providers can experience unexpected failures. Any organisation that depends on software updates—whether for security, cloud services, or enterprise applications—faces the risk of a faulty update leading to widespread system failures. While in this case, a faulty update caused the failure, it could be a cyberattack or data breach that hits your company next. While the impact most likely won’t be as significant, the prevention and recovery steps will always be the same.
A similar case occurred in 2017, when a failed software update at British Airways led to a system crash, grounding hundreds of flights and causing financial losses in the millions. In 2023, Microsoft Azure experienced a major outage due to a network configuration change gone wrong, affecting cloud services globally.
These incidents reinforce the fact that no company is immune to technical failures. The key lies in how they prepare for and respond to such crises.
The Importance of Communication in Crisis Management
One of the biggest takeaways from the CrowdStrike incident is the critical role of communication. When IT outages occur, the technical resolution is only part of the solution—how a company communicates with customers, stakeholders, and the public can significantly impact the long-term damage.
Several aspects of CrowdStrike’s communication strategy were scrutinized:
- Initial Silence – In the first critical hours, there was confusion and lack of clear messaging. Customers demanded real-time updates but received limited information.
- Delayed Leadership Response – While CrowdStrike’s technical team worked on the issue, top executives took time before addressing the public, which allowed speculation and frustration to spread.
- Transparency Efforts – Once the company fully diagnosed the issue, they provided a detailed root cause analysis and collaborated with partners like Microsoft to mitigate further damage.
So, what should companies learn from this?
The 2024 CrowdStrike outage serves as a wake-up call for cybersecurity firms and IT-dependent businesses alike. It highlights how fragile even the most advanced systems can be and underscores the importance of robust testing, crisis preparedness, and transparent communication.
For organisations looking to prevent similar reputational and financial damage, the key takeaways are clear:
- Be Transparent from the Start – Acknowledge the issue quickly, even if you don’t have all the answers yet. Customers value honesty over silence.
- Provide Frequent Updates – Even small progress updates can reassure stakeholders that the issue is being actively worked on.
- Show Empathy and Accountability – A company’s reputation is built on trust. Owning the mistake and showing genuine concern for affected customers goes a long way.
- Have a Pre-Planned Crisis Strategy – Businesses must prepare a crisis communication plan in advance, ensuring they can respond swiftly and effectively when issues arise.
- Thoroughly test updates before deployment to avoid critical system failures.
- Implement strong backup and disaster recovery solutions to minimize downtime.
- Develop a crisis communication strategy to maintain trust with stakeholders.
As businesses become increasingly digital, the consequences of IT failures will only grow. The real question isn’t whether another outage like this will happen again—but which company will handle it best when it does.
The UK’s National Cyber Security Centre (NCSC) emphasizes that effective communication in cyber incidents can help organisations mitigate long-term damage and maintain customer confidence. Companies that fail to communicate properly often suffer worse reputational damage than those that do.
What were your thoughts on the CrowdStrike outage? How should companies better prepare for IT crises? Let’s discuss in the comments below!